A Quick Glance Around Ecto v3 (ALPHA)
Ecto is the most popular persistence framework in Elixir Community.
In order to help more people to learn Ecto, I organize my personal notes, and publish them as a free online book.
Hope you guys like it!
1 Introduction
This book will act as a map of large numbers of docs, and guide you to glance over the main features of Ecto v3 by trying to construct the database layer of a blogging system.
If you want to have a deep insight of Ecto or more complicated use cases, you can read more in following materials:
Why do you take a blogging system as the example?
A blogging system is the system that everybody knows. Readers don't have to spend time to learn domain-specific things.
2 Prerequisites
Before reading this book, you should know how to write basic Elixir. That's all.
3 The Conventions
Conventions reduce the effort needed to read and understand.
3.1 Plain English
In order to help people as much as possible, I am trying to write this book in 7th-grade plain English.
English isn't my mother language. When you find any error, it would be nice if you can email me or create an issue.
3.2 The types of annotations
This is a question you will ask.
This a quote.
This a note.
This is a warning.
3.3 Notation of shell commands
The shell commands is prefixed by $ which is the default prompt for ordinary UNIX users.
For example:
$ ls -al ~
3.4 Reading official documents
When something has been explained in official documents, it won't be described again. I will guide you to read the related documents.
For example, when you see something like please read h Ecto.Schema, it means:
- read docs in a terminal by typing
h Ecto.Schemain IEx. - read docs in a web browser by visiting Ecto.Schema.
4 Setup Environments
Before moving on, we should ensure that fundamental environments are configured:
- Elixir 1.10+ is installed
- PostgreSQL is installed
There are lots of online tutorials about setting up environments, we won't describe them again.
5 Sample Application
Ecto is an Elixir library, it should be used in an Elixir project. Therefore, we should create a project before playing with Ecto.
5.1 Creating a mix project
Create a project called paper:
$ mix new paper --sup
The --sup option is required. It ensures that the generated application has a supervision tree, which is required by Ecto.
It's OK to run mix new without --sup option. But, you need to do more works later.
5.2 Adding dependencies
Two packages are required:
ecto_sqlpostgrex- database adapter for PostgreSQL
Edit mix.exs:
defp deps do [ {:ecto_sql, "~> 3.0"}, {:postgrex, ">= 0.0.0"} ] end
Fetch dependencies:
$ mix deps.get
5.3 Setting up a Repo
5.3.1 running a Mix task
You may be wondering what a Repo is. Now, just think it as a normal Elixir module. We will explain it later.
Generating a Repo:
$ mix ecto.gen.repo -r Paper.Repo
Above command will output:
* creating lib/paper
* creating lib/paper/repo.ex
* creating config/config.exs
Don't forget to add your new repo to your supervision tree
(typically in lib/paper/application.ex):
{Paper.Repo, []}
And to add it to the list of ecto repositories in your
configuration files (so Ecto tasks work as expected):
config :paper,
ecto_repos: [Paper.Repo]
As you can see, it generates lib/paper/repo.ex:
defmodule Paper.Repo do use Ecto.Repo, otp_app: :paper, adapter: Ecto.Adapters.Postgres end
About the options:
:otp_appoption indicates the location of Ecto configuration.:adapteroption indicates the database adapter.
5.3.2 adding rest configurations
Edit lib/paper/application.ex for adding Repo to supervision tree:
# ... def start(_type, _args) do children = [ # add repo to supervision tree {Paper.Repo, []} ] # ... end # ...
Edit config/config.exs for making Ecto related Mix tasks work as expected:
config :paper, ecto_repos: [Paper.Repo]
5.4 Creating database
$ mix ecto.create The database for Paper.Repo has been created
5.5 (optional) Updating configurations for mix format
Ecto has additional formatting rules. In order to apply these rules, following content should be added.
Edit .formatter.exs for formatting general Elixir code:
# Used by "mix format" [ import_deps: [:ecto], inputs: ["*.{ex,exs}", "{config,lib,test}/**/*.{ex,exs}", "priv/*/seeds.exs"], subdirectories: ["priv/*/migrations"] ]
Edit priv/repo/migrations/.formatter.exs for formatting migrations:
[ import_deps: [:ecto_sql], inputs: ["*.exs"] ]
5.6 Last
Now, Ecto is ready to communicate with the database.
6 Sample Data Model
Before writing any code, we should design a data model first.
Our data model contains 5 tables:
- authors
- posts
- tags
- permalinks
- comments
Their relationships are described in following figure:
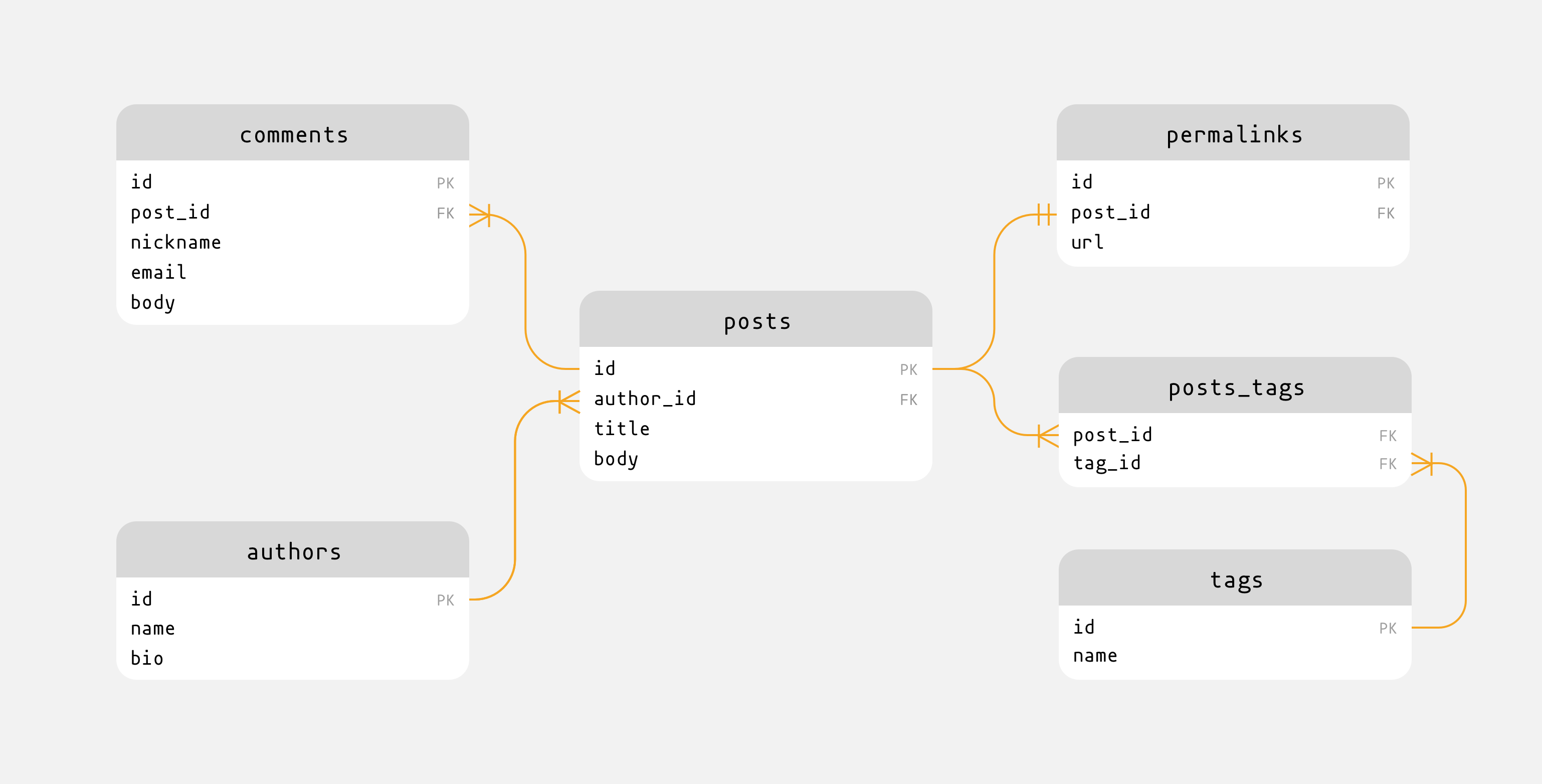
The one-to-one relationship between posts and permalinks isn't necessary for most case, it's preserved for demonstration only.
7 The Structure Of Ecto
Ecto's real purpose is translating Elixir concepts into a database language, which is SQL in most cases.
– Programming Phoenix
Before talking about Ecto in details, we will introduce the structure of Ecto first. It let us have an overview of Ecto.
Ecto includes 6 main modules which are separated in 2 packages:
ecto package - contains the core functionalities:
Repohandles all the communications between Ecto and data store.Schemaprovides DSL for mapping data source to Elixir structs.Changesetprovides functions for handling changes.Queryprovides DSL for querying.Multicontrols transactions in a clean way.
ecto_sql package - provides SQL-based adapters and database migrations:
- database-specified adapters, such as PostgreSQL, MySQL.
Migrationprovides DSL for tracking database changes in a clean way.
Why we just add ecto_sql when adding dependencies?
Because ecto is the dependency of ecto_sql, it's OK to add ecto_sql alone.
When talking about Schema, we are not saying database, but data source. That is because Schema can be used to map any data source to Elixir structs, not just database tables.
We have already known the structure of Ecto. Next, we will introduce them separately.
8 Ecto.Migration
Ecto.Migration helps developers to track database changes in a clean way.
8.1 What is a migration?
A migration is a file includes a set of instructions which changes database structure.
8.2 Creating migrations
Ecto provides a Mix task for generating a template for migrations:
$ mix ecto.gen.migration <migration name>
After executing above command, a new migration file containing a module with empty change function will be generated in priv/repo/migrations.
In relational database, there are 3 types of relationships:
| name | abbr. |
|---|---|
| one-to-one | 1-1 |
| one-to-many | 1-N |
| many-to-many | N-N |
As we saw in Sample Data Model, we have four relationships, and they cover all types of relationships:
- the relationship between authors and posts is one-to-many.
- the relationship between posts and comments is one-to-many.
- the relationship between posts and tags is many-to-many.
- the relationship between posts and permalinks is one-to-one.
Next, we will take the sample data model as an example, and demonstrate how to create migrations for all of these relationships.
When creating a migration, we generally define following things:
- table names
- columns (name, type/reference, default value, null)
- indexes
8.2.1 build relationship between authors and posts (1-N)
As we said above:
- one author has many posts.
- one post belongs to one author.
Generate a migration file:
$ mix ecto.gen.migration assoc_authors_posts
Edit the generated migration file:
defmodule Paper.Repo.Migrations.AssocAuthorsPosts do use Ecto.Migration def change do create table(:authors) do add :name, :varchar, null: false add :bio, :text timestamps() end create unique_index(:authors, [:name]) create table(:posts) do add :author_id, references(:authors, on_delete: :nilify_all) add :title, :varchar, null: false add :body, :text, null: false timestamps() end end end
Apply the new migration:
$ mix ecto.migrate
8.2.2 build relationship between posts and permalinks (1-1)
As we said above:
- one post has one permalink.
- one permalink belongs to one post.
Generate a migration file:
$ mix ecto.gen.migration assoc_posts_permalinks
Edit the generated migration file:
defmodule Paper.Repo.Migrations.AssocPostsPermalinks do use Ecto.Migration def change do create table(:permalinks) do add :post_id, references(:posts, on_delete: :delete_all), null: false add :url, :varchar, null: false timestamps() end create unique_index(:permalinks, [:url]) end end
Apply the new migration:
$ mix ecto.migrate
8.2.3 build relationship between posts and comments (1-N)
As we said above:
- one post has many comments.
- one comment belongs to one post.
Generate a migration file:
$ mix ecto.gen.migration assoc_posts_comments
Edit the generated migration file:
defmodule Paper.Repo.Migrations.AssocPostsComments do use Ecto.Migration def change do create table(:comments) do add :post_id, references(:posts, on_delete: :delete_all), null: false add :email, :varchar, null: false add :nickname, :varchar, null: false add :body, :text, null: false timestamps() end end end
Apply the new migration:
$ mix ecto.migrate
8.2.4 build relationship between posts and tags (N-N)
As we said above:
- one post has many tags.
- one tag has many posts.
Generate a migration file:
$ mix ecto.gen.migration assoc_posts_tags
Edit the generated migration file:
defmodule Paper.Repo.Migrations.AssocPostsTags do use Ecto.Migration def change do create table(:tags) do add :name, :varchar, null: false timestamps() end create unique_index(:tags, [:name]) create table(:posts_tags, primary_key: false) do add :post_id, references(:posts, on_delete: :delete_all), null: false add :tag_id, references(:tags, on_delete: :delete_all), null: false end create unique_index(:posts_tags, [:post_id, :tag_id]) create index(:posts_tags, [:post_id]) create index(:posts_tags, [:tag_id]) end end
Apply the new migration:
$ mix ecto.migrate
8.3 Applying migrations
We have introduced how to apply migration in above sections. Read more details at:
$ mix help ecto.migrate
8.4 Rolling back migrations
Read more details at:
$ mix help ecto.rollback
8.5 Available column types
When creating migrations, we have specified some column types, such as :varchar or :text. These data types supported by database can be used directly in migrations. And, data types with database-specific options can be used, too. Such as:
:"int unsigned":"time without time zone"- …
Besides, Ecto also maps primitive types to the appropriate database data types by the database adapters. Such as:
- map
:stringto:varchar(255) - map
:binaryto:bytea - …
Ecto defines the mapping at ecto_sql package. For PostgreSQL, the details can be found here.
When using Ecto with PostgreSQL, I would like to use :varchar and :text, instead of :string.
:varcharfor one line text:textfor multiple lines text
In PostgreSQL, the performance of them is the same.
8.6 Adding index
Read more details at h Ecto.Migration.index.
8.7 The options of references
Ecto.Migration.references have two options which should be explained here - :on_delete and :on_update.
The official docs don't talk much about them. But, we can know the details by reading related source code and corresponding docs of PostgreSQL.
8.7.1 the :on_delete option
The :on_delete option specifies the behavior of referencing rows when a referenced row is deleted. Following is the available values.
:delete_all- PostgreSQL clause:
ON DELETE CASCADE - description: The referencing rows will be deleted.
- PostgreSQL clause:
:nilify_all- PostgreSQL clause:
ON DELETE SET NULL - description: The foreign key of referencing rows will be set as
NULL.
- PostgreSQL clause:
:restrict- PostgreSQL clause:
ON DELETE RESTRICT - description: Prevent deletion of a referenced row.
- PostgreSQL clause:
:nothing(default behavior)- PostgreSQL clause:
NO ACTION - description: Do nothing. (It will cause an error when checking constrains.)
- PostgreSQL clause:
8.7.2 the :on_update option
Because primary key won't be changed after the record has been created, this option isn't used frequently.
The :on_update option specifies the behavior of referencing rows when the column of a referenced rows is updated. Following is the available values.
:update_all- PostgreSQL clause:
ON UPDATE CASCADE - description: The foreign key of referencing rows will be updated according to the referenced rows.
- PostgreSQL clause:
:nilify_all- PostgreSQL clause:
ON UPDATE SET NULL - description: The foreign key of referencing rows will be set as
NULL.
- PostgreSQL clause:
:restrict- PostgreSQL clause:
ON UPDATE RESTRICT - description: Prevent update of a referenced row.
- PostgreSQL clause:
:nothing(default behavior)- PostgreSQL clause:
NO ACTION - description: Do nothing. (It will cause an error when checking constrains.)
- PostgreSQL clause:
8.8 Practices
8.8.1 ensure migrations can be rolled back
When adding a new migration, we should ensure that we can roll them back.
Generally, Ecto can infer the rollback behavior of change/0 function in the migrations. When it can't, consider using up/0 and down/0.
8.8.2 should I editing an existing migration?
If the migration hasn't been committed to VCS, you are free to edit an existing one.
If the migration has been committed and you are not the only one in the team, you'd better creating a new one.
8.10 Last
The database is ready, it's time to insert data into it.
9 Ecto.Repo
Ecto.Repo provides basic API for communicating with database.
9.1 The Repository Pattern
Ecto adopts The Repository Pattern for accessing underlying data store. In this pattern, there's a role called Repository who controls all the communications between Ecto and data store.
The general lifecyle of queries looks like:
- All the queries are submitted to the Repository.
- The Repository transforms the queries and send them to data store.
- The Repository handles the responses from data store and transforms them into easy-to-use format.
The keypoint is the Repository acts as a gateway of data store. When you want to make changes to data store, talk to Repository.
9.2 Repository in Ecto
Ecto.Repo is the so-called Repository in Ecto.
But, Ecto.Repo isn't used directly. It should be used in a self-created module. When creating the sample application, we have created the module called Paper.Repo.
For brevity, in the following sections, I will use Repo to represent the self-created module - Paper.Repo, and use Ecto.Repo to represent the original module.
9.3 Low level API for CRUD
Repo provides low level API to complete CRUD operations directly.
| Operation Name | Function Name |
|---|---|
| CREATE | Repo.insert_all |
| READ | Repo.query (an alias for Ecto.Adapters.SQL.query/4) |
| UPDATE | Repo.update_all |
| DELETE | Repo.delete_all |
All *_all functions support :returning option for selecting which fields to return. Read their documents for more details.
When using Repo.query. you will find the return value is hard to parse. And, working with SQL directly is clumsy and unsafe (SQL injection).
Ecto.Query is the better choice for queries.
9.4 Extending Repo
Repo is a regular Elixir module, we can extend it as normal. It is useful when we want to:
- encapsulate tediously long options for particular functions.
- add functions that Ecto doesn't support currently.
- …
For example, adding a counting function:
defmodule Paper.Repo do use Ecto.Repo, otp_app: :paper, adapter: Ecto.Adapters.Postgres def count(table) do aggregate(table, :count, :id) end end
Call the added function:
Paper.Repo.count("authors")
9.5 Last
Read more details at h Ecto.Repo.
10 Ecto.Schema
Ecto.Schema provides DSL for mapping data source to Elixir structs.
10.1 Creating schemas
Like creating a migration, when creating a schema, we generally define following things:
- table names
- fields (name, type/relationship, default value)
10.1.1 creating a context first
A context is a concept introduced by Phoenix. It is a dedicated module that expose and group related functionality.
Here, we will just create a context without talking much about it. If you are interested in the details of contexts, please read the official docs.
Our context will be named as CMS. Now, let's create it by editing lib/paper/cms.ex:
defmodule Paper.CMS do end
So far, the context is empty, because we have no public API for this context.
10.1.2 association related macros
Ecto.Schema provides following macros for indicating the associations between schemas:
| relationship | macros |
|---|---|
| one-to-one | has_one / belongs_to |
| one-to-many | has_many / belongs_to |
| many-to-many | many_to_many with :join_through option |
It's hard to understand them without any example. Next, we will create necessary schemas step by step. When you have questions about them, please read respective documents like h Ecto.Schema.many_to_many.
10.1.3 creating a schema for authors
Edit lib/paper/cms/author.ex:
defmodule Paper.CMS.Author do use Ecto.Schema alias Paper.CMS.Post schema "authors" do field :name, :string field :bio, :string has_many :posts, Post timestamps() end end
schema and field do two things:
- define the mapping between schema and database.
- define a struct for current schema.
10.1.4 creating a schema for permalinks
Edit lib/paper/cms/permalink.ex:
defmodule Paper.CMS.Permalink do use Ecto.Schema alias Paper.CMS.Post schema "permalinks" do belongs_to :post, Post field :url, :string timestamps() end end
10.1.5 creating a schema for comments
Edit lib/paper/cms/comment.ex:
defmodule Paper.CMS.Comment do use Ecto.Schema alias Paper.CMS.Post schema "comments" do belongs_to :post, Post field :nickname, :string field :email, :string field :body, :string timestamps() end end
10.1.6 creating a schema for tags
Edit lib/paper/cms/tag.ex:
defmodule Paper.CMS.Tag do use Ecto.Schema alias Paper.CMS.Post schema "tags" do many_to_many :posts, Post, join_through: "posts_tags" field :name, :string timestamps() end end
10.1.7 creating a schema for posts
Edit lib/paper/cms/post.ex:
defmodule Paper.CMS.Post do use Ecto.Schema alias Paper.CMS.Author alias Paper.CMS.Permalink alias Paper.CMS.Comment alias Paper.CMS.Tag schema "posts" do belongs_to :author, Author has_one :permalink, Permalink has_many :comments, Comment many_to_many :tags, Tag, join_through: "posts_tags" field :title, :string field :body, :string timestamps() end end
10.1.8 available field types
- built-in types
- Read more details at Primative types section in
h Ecto.Schema. - custom types
- Read more details at Custom types section in
h Ecto.Schema.
10.2 Starting IEx
We have created all required schemas, it is time to do some experiments with them.
Before starting IEx, it is better to add configurations for it. The configurations help us type less every time we starting IEx.
Edit .iex.exs:
import Ecto.Query alias Paper.Repo alias Paper.CMS.{Author, Permalink, Tag, Comment, Post}
Now, let's start it:
$ iex -S mix
10.3 CRUD
10.3.1 insert
Ecto provides following functions which can be used with schemas:
Repo.insertRepo.insert!Repo.insert_allRepo.insert_or_updateRepo.insert_or_update!
10.3.1.1 inserting without association
Authors and tags can be inserted without associations:
# insert authors %Author{name: "Spike", bio: "I have a cool name!"} |> Repo.insert() %Author{name: "Julia", bio: "I have a beautiful name!"} |> Repo.insert() Repo.count("authors") #=> 2 %Tag{name: "Life"} |> Repo.insert() %Tag{name: "Art"} |> Repo.insert() %Tag{name: "Religion"} |> Repo.insert() Repo.count("tags") #=> 3
But, there's a problem here - the data is NOT validated before inserting to database. This means we can insert anything we want. Try to insert a piece of useless data:
%Author{name: "", bio: ""} |> Repo.insert()
Obviously, above useless data is not what we want. If you want to validate the data before inserting to database, Ecto.Changeset which will be introduced later is needed.
10.3.1.2 inserting with associations
Inserting with associations needs Ecto.Changeset which will be introduced later.
10.3.2 query
Ecto provides following functions which can be used with schemas:
Repo.allRepo.oneRepo.one!Repo.getRepo.get!Repo.get_byRepo.get_by!- …
Query the data we have inserted to database:
Repo.all(Author) Repo.get(Author, 2) Repo.get_by(Author, %{name: "Julia"}) # ...
If you need build complex query, try to use Ecto.Query which will be introduced later.
10.3.3 update
Ecto provides following functions which can be used with schemas:
Repo.updateRepo.update!Repo.update_all
Updating needs Ecto.Changeset which will be introduced later.
10.3.4 delete
Ecto provides following functions which can be used with schemas:
Repo.deleteRepo.delete!Repo.delete_all
Delete one author:
author = Repo.get_by(Author, %{name: ""}) case Repo.delete(author) do {:ok, _author} -> "Deleted successfully." {:error, _changeset} -> "Something went wrong." end
10.4 Last
As you see, without Ecto.Changeset, we can't insert or update data reliably.
Next, we will introduce Ecto.Changeset.
11 Ecto.Changeset
Ecto.Changeset encapsulates the whole policy for changing data, including allowed fields, detecting changes and validations.
In short, it defines the updating policies which make sure the database is changed safely.
11.1 About %Ecto.Changeset{}
%Ecto.Changeset{} is the struct holding all the changes which will be performed to the database.
For brevity, in the following sections, I will use %Changeset{} instead of %Ecto.Changeset{}.
11.2 Basics
General updating process is broke up into 3 stages:
- getting changes
- validating changes
- sending changes to database
raw_data |> get_changes |> validate_changes |> send_changes_to_database
Next, we will talk about each step in detail.
11.3 Getting Changes
The first step is getting changes.
Depending on where the data is coming from, this step can be done in two different ways.
11.3.1 handling external data
External data is the data which is coming outside of your application code, such as:
- user forms
- API calls
- command line
- CSV file
- …
When working with changes provided external data, we should suppose that the data is dirty, then, cast and filter them into legal changes.
In Ecto:
- casting means type conversion, like converting string to integer.
- filtering means removing unused data.
Handling external data can be done with Ecto.Changeset.cast. It casts and filters external data, then convert them into :changes field of %Changeset{}.
params = %{ "name" => "Vicious", "bio" => "I have an evil name!", "true_words" => "I want to be a good man." } changeset = cast(%Author{}, params, [:name, :bio])
Read more details at h Ecto.Changeset.cast.
11.3.2 handling internal data
Internal data is the data which is coming from application code.
Because this type of data comes from application code, it's unnecessary to waste time to cast and filter them.
Handling internal data can be done with Ecto.Changeset.change. It merges the internal data into :changes field of %Changeset{} directly, without casting and filtering.
Create a new changeset from a new schema:
import Ecto.Changeset changeset = change(%Tag{name: "Music"})
Create a changeset from an existing schema:
import Ecto.Changeset author = %Author{name: "unknown", bio: ""} |> Repo.insert() changeset = change(author) # add data when calling change function changeset = change(author, name: "Vicious") changeset = change(author, name: "Vicious", bio: "I have an evil name!") # change function can be called multiple times changeset = author |> change(name: "Vicious") |> change(bio: "I have a evil name!")
Read more details at h Ecto.Changeset.change.
11.3.3 last
After getting changes, we have a %Changeset{} which represents changes.
11.4 Validating Changes
When working with changes provided by external data, we should also validate the changes before sending the to database.
Ecto provides two kinds of utilities for validating. They perform similar functions, but differ in implementation:
- validations
- constraints
11.4.1 validations
Validations are functions provided by Ecto.Changeset. They accept a changeset, return a changeset.
11.4.1.1 built-in validations
Built-in validations are in form of Ecto.Changeset.validate_*.
params = %{ "name" => "x" } changeset = %Author{} |> cast(params, [:name, :bio]) |> validate_required([:name, :bio]) |> validate_length(:name, min: 3, max: 50) changeset.valid? #=> false
When passing all the validations, changeset.valid? will be true. Or, changeset.valid? will be false, and the details of validation error can be found at changeset.errors.
11.4.1.2 custom validations
Ecto provides support for custom validations in case that you need validtions which are not supported by it.
Read more details at h Ecto.Changeset.validate_change.
11.4.2 constraints
Like validations, contraints are functions provided by Ecto.Changeset, too. It allows developers to use underlying relational database features to maintain database integrity. Such as, preventing duplicated username in a user management system.
They accept a changeset, return a changeset, just like validations.
When using a constraint, you need:
- define database constraints
- catch constraint errors
Next, we will introduce these 2 steps with unique_constraint/3.
Unlike validations, constraints won't run before hitting database. Instead, they run when Ecto accepts constraint errors returned from database.
Related terminologies:
- constraint: an explicit constraint in database level. Generally, it is defined via migrations.
- constraint error: the
Ecto.ConstraintError. It occurs when Ecto detecting a constraint problem issued by database. - changeset constraint: an annotation added to the changeset that allows Ecto to convert constraint errors into changeset error messages.
- changeset error messages: readable error messages for users.
11.4.2.1 defining database constraints
Constraints are enforced by database. Because of that, they should be defined in database level.
In order to manage database constraints, it is better to create them by using migrations. Just like we did when creating migrations.
create unique_index(:authors, [:name])
11.4.2.2 catching constraint errors
If a constraint error isn't catched, it will be raised as Ecto.ConstraintError.
# create two authors with the same name, which will raise a constraint error. %Author{name: "Spike", bio: ""} |> Repo.insert() %Author{name: "Spike", bio: ""} |> Repo.insert() #=> # (Ecto.ConstraintError) constraint error when attempting to insert struct: # # - authors_name_index (unique_constraint) # # If you would like to stop this constraint violation from raising an # exception and instead add it as an error to your changeset, please # call `unique_constraint/3` on your changeset with the constraint # `:name` as an option. # # The changeset has not defined any constraint.
In order to catch it, an Ecto.Changeset.*_constraint-like function should be used:
%Author{name: "Spike", bio: ""} |> change() |> unique_constraint(:name) |> Repo.insert() #=> {:error, changeset}
As you can see, Ecto.ConstraintError is catched and transformed as an error in changeset.
11.4.3 execution rules of validations and constraints
- execute all of valiations in order:
- if succeed to execute one validation, execute next validation.
- if failed to execute one validation, execute next validation, too. But, all of constraints will not be executed any more.
- execute all of constraints in order:
- if succeed to execute one constraint, execute another constraint.
- if failed to execute one constraint, the rest of constraints will not be executed any more.
11.4.4 mixins
Mixins are functions mix the features of validations and constraints. They have following features:
- their execution rules are same as validations.
- they communicates with database to validating values.
Mixin is not a terminology in Ecto. I name them in this way, personally.
11.4.4.1 Ecto.Changeset.unsafe_validate_unique
Read details at h Ecto.Changeset.unsafe_validate_unique.
Ecto.Changeset.unsafe_validate_unique isn't a replacement of Ecto.Changeset.unique_constraint. It just used for providing a early feedback for users. Generally, it is used in this way:
%Author{} |> cast(params, [:name, :bio]) |> validate_required(:name) |> unsafe_validate_unique(:name, Repo) |> validate_length(:name, min: 3) |> unique_constraint(:name)
11.4.5 rendering errors
Ecto doesn't provide solutions for rendering changeset.errors. When you need to render them, consider using Ecto.Changeset.traverse_errors.
11.5 Sending Changes to database
Last step, send %Changeset{} to database with functions provided by Repo, such as Repo.insert, Repo.update, etc.
11.6 Adding updating policies for schemas
We have known all the necessary things about Ecto.Changeset. It's time to write update policies for schemas.
11.6.1 Adding updating policy for Author
Edit lib/paper/cms/author.ex:
import Ecto.Changeset alias Paper.Repo @doc false def changeset(author, attrs) do author |> cast(attrs, [:name, :bio]) |> validate_required(:name) |> validate_length(:name, min: 3, max: 50) |> validate_length(:bio, max: 400) |> unsafe_validate_unique(:name, Repo) |> unique_constraint(:name) end
11.6.2 Adding updating policy for Post
Edit lib/paper/cms/post.ex:
import Ecto.Changeset @doc false def changeset(post, attrs) do post |> cast(attrs, [:title, :body]) |> validate_required([:title, :body]) |> validate_length(:title, min: 3, max: 50) end
11.6.3 Adding updating policy for Permalink
Edit lib/paper/cms/permalink.ex:
import Ecto.Changeset alias Paper.Repo @doc false def changeset(permalink, attrs) do permalink |> cast(attrs, [:url]) |> validate_required(:url) |> unsafe_validate_unique(:url, Repo) |> unique_constraint(:url) end
11.6.4 Adding updating policy for Comment
Edit lib/paper/cms/comment.ex:
import Ecto.Changeset @doc false def changeset(comment, attrs) do comment |> cast(attrs, [:nickname, :email, :body]) |> validate_required([:nickname, :email, :body]) |> validate_length(:nickname, min: 3, max: 50) |> validate_length(:email, max: 200) end
11.6.5 Adding updating policy for Tag
Edit lib/paper/cms/tag.ex:
import Ecto.Changeset alias Paper.Repo @doc false def changeset(tag, attrs) do tag |> cast(attrs, [:name]) |> validate_required([:name]) |> validate_length(:name, min: 3, max: 50) |> unsafe_validate_unique(:name, Repo) |> unique_constraint(:name) end
11.7 Last
Read more details at Ecto.Changeset.
12 Filling the Context
We have created:
- an empty context when creating schemas.
- schemas
- changesets
It's time to put them together.
Open lib/paper/cms.ex, add general CRUD functions:
defmodule Paper.CMS do @doc """ The CMS context. """ alias Paper.Repo alias Paper.CMS.Author alias Paper.CMS.Post alias Paper.CMS.Comment alias Paper.CMS.Permalink alias Paper.CMS.Tag @doc false def list_authors do Repo.all(Author) end @doc false def get_author!(id), do: Repo.get!(Author, id) @doc false def create_author(attrs \\ %{}) do %Author{} |> Author.changeset(attrs) |> Repo.insert() end @doc false def update_author(%Author{} = author, attrs) do author |> Author.changeset(attrs) |> Repo.update() end @doc false def delete_author(%Author{} = author) do Repo.delete(author) end @doc false def change_author(%Author{} = author, attrs \\ %{}) do Author.changeset(author, attrs) end # Create rest functions for other schemas by youself. end
13 Ecto.Query
Ecto.Query provides DSL for querying. It makes querying simple and elegant.
Ecto.Queryprovides all available keywords.Ecto.Query.APIprovides all available functions.
13.1 Syntax
There are two types of syntax when using Ecto.Query:
- keyword syntax
- expression syntax
Following SQL can be wrote into above two types of syntax:
SELECT a.name, a.bio FROM authors AS a
13.1.1 keyword syntax
query = from a in "authors", select: [a.name, a.bio] Repo.all(query)
13.1.2 expression syntax
query = "authors" |> select([a], [a.name, a.bio]) Repo.all(query)
13.1.3 How to choose syntax?
The syntax you choose depends on your taste and the problems you're solving:
- keyword syntax: convenient for pulling together ad-hoc queries and solving one-off problems.
- expression syntax: better for building an application's unique complex layered query API.
Each syntax has its advantages.
– Programming Phoenix
Personally, I think the keyword syntax is more convinient to write. Because of that, following queries will be wrote in Keyword Syntax.
13.2 Basic usage
A query is created and used in following steps:
- creating a query
- committing a query
13.2.1 creating a query
When creating a query, you can use a table name string or a schema. All of them have implemented Ecto.Queryable protocol.
Use a table name string:
query = from a in "authors", where: a.id == 2, select: [:name]
If not using a schema when building a query, the :select option is required. Or, Ecto will raise an error.
Use a schema:
query = from a in Author, where: a.id == 2
13.2.2 committing a query
Use Repo.all, Repo.one and so on for committing a query:
Repo.all(query)
13.3 Debugging
Ecto.Adapters.SQL.to_sql/3 is used for translating a query to corresponding SQL statement. We can use this function to help us inspecting the details of queries.
For example:
query = from a in "authors", where: a.id == 2, select: [:name] Ecto.Adapters.SQL.to_sql(:all, Repo, query) #=> {"SELECT a0.\"name\" FROM \"authors\" AS a0 WHERE (a0.\"id\" = 2)", []} # equal to Repo.to_sql(:all, query) #=> {"SELECT a0.\"name\" FROM \"authors\" AS a0 WHERE (a0.\"id\" = 2)", []}
13.4 Dynamic values
13.4.1 pin operator
In Ecto, ^ (pin operator) is used for marking values or expressions that need interpolation in an Ecto query.
^ is named as "caret" in English.
When Ecto.Query is converted into a SQL statement, values and expressions marked by ^ will become parameterized values.
Parameterized values provides protection against SQL-injection attacks.
An example:
author_name = "Spike" query = from "authors", where: [name: ^author_name], select: [:id, :name] Repo.all(query) #=> SELECT a0."id", a0."name" FROM "authors" AS a0 WHERE (a0."name" = $1) ["Spike"]
13.4.2 type conversion
author_id = 2 query = from "authors", where: [id: ^author_id], select: [:name] Repo.all(query) #=> [%{name: "Spike"}] author_id = "2" query = from "authors", where: [id: ^author_id], select: [:name] Repo.all(query) #=> Type Error, you have to make type conversion manually. artist_id = "2" query = from "authors", where: [id: type(^author_id, :integer)], select: [:name] Repo.all(query) #=> [%{name: "Spike"}]
type function is defined in Ecto.Query.API.
Now, type conversion seems tedious. But, after using Schema, the conversion will be done automatically.
13.5 Query bindings
A query binding is a variable referring to the table of the query. You can treat it as table alias in SQL.
There are two types of bindings:
- positional bindings
- named bindings
Read more details at Composition section in h Ecto.Query.
13.5.1 which one should I use?
When a query is small, using positional bindings would be fine.
But, when a query is large and contains joins across several tables, using positional bindings would make tracking bindings difficult. Therefore, named bindings is preferred.
13.6 Query API
Read h Ecto.Query.API for a complete list of all available API.
13.7 Raw SQL
Best abstractions offer escape hatch.
– Programming Phoenix
Ecto can't represent all possible queries with its own syntax, so it provides two backup plans:
Ecto.Query.API.fragment/1: generate a SQL fragment which can be inserted into a Ecto query.Repo.query/Repo.query!: run a raw SQL with parameterized values.
Read more details in their docs.
Although Ecto.Query.API.fragment/1 is a function provided by h Ecto.Query.API, but I still put it in this section because of their correlation.
13.8 Filtering with where
Ecto.Query provides two macros for filtering:
whereor_where
13.9 Combining results with unions
When using unions, the two queries need to have result sets with the same column names and data type.
Supported unions:
| macro name | description |
|---|---|
union |
remove duplicated items. |
union_all |
don't remove duplicated items, faster. |
intersect |
remove duplicated items. |
intersect_all |
don't remove duplicated items, faster. |
except |
remove duplicated items. |
except_all |
don't remove duplicated items, faster. |
13.10 Ordering with order_by
Read more details at h Ecto.Query.order_by.
When sorting rows by multiple columns specified by order_by, the records will grouped and sorted by first column, then by the second column, and so on.
When ordering, you should also notice NULL value. Some databases put them first, others put them last. If you want to control the order explicitly, try following options:
:asc_nulls_last:asc_nulls_first:desc_nulls_last:desc_nulls_first
13.11 Grouping with group_by
When you want to filtering rows after grouping, you should use having and or_having, rather than where and or_where.
Read more details at h Ecto.Query.group_by.
13.12 Joins
Joins are required when query across multiple tables at once.
Read more details at h Ecto.Query.join.
13.13 Composable Queries
Ecto queries are composable. This feature can help us to break large queries into small reusable queries. Small queries are easy to read and maintain, which is good for us.
The small reusable queries are composed into a query via Ecto.Queryable protocol.
Read more details at Composition section in h Ecto.Query.
13.14 Using a schema
As you see, we are using table name string in above queries. But, with a schema, we can get better experiences, because it contains:
- the type info of fields, therefore, type conversion can be done automatically.
- the list of fields, therefore,
:selectoption isn't necessary when querying.
Give it an example. Without a schema, we have to do type conversion and specify the :select manually:
author_id = "2" query = from "authors", where: [id: type(^author_id, :integer)], select: [:name] Repo.all(query)
With a schema, query can be simpler:
author_id = "2" query = from Author, where: [id: ^author_id] Repo.all(query)
13.15 Tips
13.15.1 specifying data structure with :select option
:select option is not only for specifying the fields returned, but also the data structure returned.
query = from a in "authors", where: a.id == 2, select: [a.name] Repo.all(query) #=> [["Spike"]]
query = from a in "authors", where: a.id == 2, select: %{name: a.name} Repo.all(query) #=> [%{name: "Spike"}]
The output become a list of map now.
13.15.2 other ways to use queries
Besides reading data, queries can be used with Repo.*_all functions for updating or deleting data.
from a in "authors", where: a.bio == "" |> Repo.update_all(set: [bio: "Hello World!"]) from a in "authors", where: a.bio == "Hello World!" |> Repo.delete_all()
By using queries in this way, we can update or delete data precisely.
13.16 Last
Read more at h Ecto.Query.
14 Association
Relational Database Management System like PostgreSQL does a lot of works to help developers define and enforce the relationships between tables.
Instead of treating the database as dumb storage, Ecto uses the strengths of the database to help keeping the data consistent.
– Programming Phoenix
So far, we have talked about data without associations. Now, let's introduce data with associations.
In this chapter, we will use the associtaion between authors and posts as the example:
- one author has many posts.
- one post belongs to one author.
And, records in authors table are called as parent records, and records in posts table are called as children records.
Q: How to distinguish parent from child?
A: At schema level, the schema that calls has_* is the parent schema, the one calls belongs_to is the child schema. At database level, the table contains foreign key is the child table, another table is the parent table.
14.1 What is association?
Ecto not only supports relational database, but also other types of data sources. Because of that, it's not suitable to describe the relationship between data sources by the terminology - relationship which has been used in relational database.
Association is the term which is used by Ecto to describe the relationship between data sources. You can think it as a superset of relationship.
14.2 Insert / Update
When inserting or updating records, there's two questions should be answered first:
- What is the type of records? parent or child?
- If the type is child, how many children records do you want to insert or update?
14.2.1 insert / update a parent record
Just insert or update it, nothing to say.
14.2.2 insert a child record
When inserting a child record, Ecto.build_assoc is a great choice. You pass it a parent record and the name of association. It returns a new generated child record with the foreign key setting to the parent record:
author = Repo.get_by(Author, name: "Spike") # bulid a new child record without filling fields Ecto.build_assoc(author, :posts) |> Repo.insert!() # bulid a new child record with filling fields Ecto.build_assoc(author, :posts, %{title: "Hello World!", body: "..."}) |> Repo.insert!() # bulid a new child record with filling fields by change() Ecto.build_assoc(author, :posts) |> change(%{title: "Hello World", body: "..."}) |> Repo.insert!()
Use Ecto.Changeset.put_assoc:
author = Repo.get_by(Author, name: "Spike") %Post{title: "Hello world", body: "..."} |> change() |> put_assoc(:author, author) |> Repo.insert!()
We can also set author_id field directly.
Use struct:
author = Repo.get_by(Author, name: "Spike") %Post{title: "Hello world", body: "", author_id: author.id} |> Repo.insert!()
Use Ecto.Changeset.put_change:
author = Repo.get_by(Author, name: "Spike") %Post{title: "Hello world", body: ""} |> change() # It is same with =Ecto.Changeset.put_assoc=, but more verbose. |> put_change(:author_id, author.id) |> Repo.insert!()
14.2.3 update a child record
Get a record, update it with Ecto.Changeset.
14.2.4 handling children records as a whole
14.2.4.1 handling external data
For handling external data, we will use Ecto.Changeset.cast_assoc.
Ecto.Changeset.cast_assoc works by comparing following data, and generate proper operations.
- current children records which are preloaded from database.
- parameters for given association which are retrieved from
changeset.params.
It takes a changeset, the name of association, and the optional options:
params = %{ "posts" => [ %{"title" => "Hello World", "body" => "..."}, %{"title" => "Hello World", "body" => "..."} ] } Repo.get_by(Author, name: "Spike") |> Repo.preload(:posts) |> change() |> cast(params, []) |> cast_assoc(:posts) |> Repo.update!()
Read more details at h Ecto.Changeset.cast_assoc.
14.2.4.2 handling internal data
For handling internal data, we will use Ecto.Changeset.put_assoc.
Ecto.Changeset.put_assoc works by associating existing children records to current record.
It takes a changeset, the name of association, and the records we want to put into the association:
Repo.get_by(Author, name: "Spike") |> Repo.preload(:posts) # preload is required |> change() |> put_assoc(:posts, [ %Post{title: "Software Design", body: "..."}, %Post{title: "Programming Ecto", body: "..."} ]) |> Repo.update!()
Before making changes to existing associations, the association must be preloaded, just like above example code. But, if the parent record hasn't persisted to database, preloading association can be ignored, such as:
%Author{name: "Vicious"} |> change() |> put_assoc(:posts, [ %Post{title: "12 Principles", body: "..."}, %Post{title: "Software Design", body: "..."} ]) |> Repo.insert!()
Read more details at h Ecto.Changeset.put_assoc.
14.2.4.3 handling records which are replaced
When handling children records as a whole, we should consider a question: Which action should be applied on children records which are replaced?
What is meaning of being replaced?
Imagine a author has many posts where the posts has IDs 1, 2 and 3. If you call
cast_assoc/3passing only the IDs 1 and 2. Ecto will consider 3 is being replaced.
Ecto.Schema.* provides :on_replace option to answer this question:
has_onehas:raise/:mark_as_invaild/:nilify/:update/:delete.has_manyhas:raise/:mark_as_invaild/:nilify/:delete.many_to_manyhas:raise/:mark_as_invaild/:delete.
:on_replace policy is only triggered when calling Ecto.Changeset.put_assoc and Ecto.Changeset.cast_assoc. If you don't use them, it's not necessary to set this option.
No matter which :on_replace policy we choose, Ecto will compare the records or parameters we passed in with the persisted children records in database.
As we said before, Ecto doesn't support lazy loading. the persisted children records in database have to be loaded manually.
This is why we need to preload association before calling Ecto.Changeset.put_assoc and Ecto.Changeset.cast_assoc.
Read more details in the Associations, embeds and on replace section of h Ecto.Changeset.
14.3 Query
14.3.1 load associations
Associations must be preloaded manually.
Ecto doesn't support lazy loading, we have to preload association manually. It helps to avoid N+1 querying problem.
Load associations when querying:
query = from Author, preload: :posts authors = Repo.all(query)
Load associations after querying:
authors = Author |> Repo.all() |> Repo.preload(:posts)
Above two methods will query database twice regardless of the count of authors:
- one for getting all authors
- one for getting all posts
If you wanna get authors and associated posts in one query, join can help you:
query = from a in Author, join: p in assoc(a, :posts), where: p.title == "Hello World", preload: [posts: p] Repo.all(query)
query = from a in Author, join: p in Post, on: a.id == p.author_id, where: p.title == "Hello World", preload: [posts: p] Repo.all(query)
14.3.2 load associations only
author = Repo.get_by(Author, %{name: "Spike"}) query = Ecto.assoc(author, :posts) Repo.all(query)
14.3.3 load nested associations
query = from Artist, preload: [posts: :comments] artists = Repo.all(query)
Ecto will return all artists with posts, and all comments in posts.
14.4 Delete
14.4.1 delete a child record
Get a record, delete it.
14.4.2 delete a parent record
If a parent record has no child record, it is safe to delete it.
But, if a parent record has children records, you have to consider a question: which action should be applied on its children records when deleting the parent record? The :on_delete option of Ecto.Migration.references provides the answer to this question.
has_one / has_many / many_to_many in Ecto.Schema provide :on_delete option, too. But, you SHOULD NEVER USE THEM. Because these options:
- CAN NOT guarantee database integrity.
- only triggered by
Ecto.Repo.delete/2, not includingEcto.Repo.delete_all/2.
When the relationship between parent and child is has_*, and :nothing policy of :on_delete option is used, Ecto will raise an constraint error when checking constraint. If the error is valuable for users, you can catch this error by Ecto.Changeset.no_assoc_constraint which convert error to human-readable message. Read h Ecto.Changeset.no_assoc_constraint for more details.
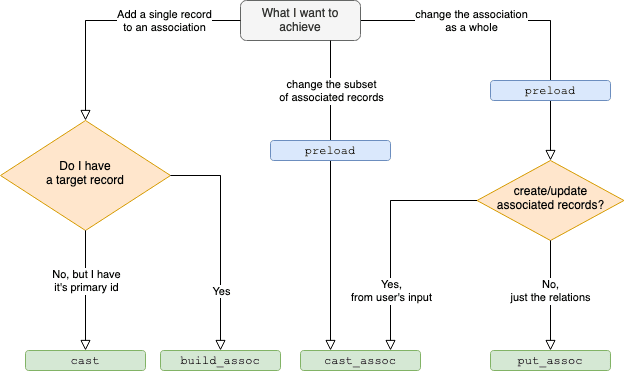
14.5 Note for cast / cast_assoc / put_assoc / build_assoc
cast_associs used for casting external data, it will result in multipleINSERT/UPDATE/DELETEqueries.put_associs used for defining associations between existing records.build_associs used for building a record associated with another record.
15 Seeding
Seeding is a mechanism to populate tables with relevant data programatically.
In Elixir, we can create a script to do this, and make sure that seed scripts is idempotent, because they may be executed multiple times.
15.1 Handle uniqueness with upsert
You may handling uniqueness problem in this way:
Repo.get_by(Tag, name: "Tech") || Repo.insert!(%Tag{name: "Tech"})
But, above operation is unsafe - not an atomic operation. In certain conditions, Ecto will try to insert two same data at the same time, which will cause a database constraint error.
Instead, we shouldn't handle this uniqueness problem by ourselves. Just insert the data, and let database manage the conflict data - this feature is known as upsert.
In Ecto, the upsert feature is implemented as :on_conflict option of Repo.insert!. A possible example would be:
# ignore conflicting data Repo.insert!(%Tag{name: "Tech", on_conflict: :nothing})
There are lots of available values for :on_conflict option, read more details at h Repo.insert.
Upsert feature is often database specific, make sure that your database supports it before using.
PS: Choose PostgreSQL, everything will be fine.
15.2 upsert with returning the record
on_conflict: :nothing will only return the struct containing conflict fields. If you insert a tag with specified name, and want to get the tag no matter it's conflict or not, use following code:
# force update on conflict record, which returns the struct with all fields. Repo.insert( %Tag{name: name}, on_conflict: {:replace, [:name]}, conflict_target: :name, returning: true )
15.3 Populate data with Schema
Data can be inserted with Schema easily, even associated data.
Repo.insert( %Author{ name: "Jet", posts: [ %Post{ title: "Hello World!", body: "Here you go!" } ] } )
16 Transactions
Ecto supports transactions through Repo.transcation. There are 2 ways to call this function:
- with a function containing the operations will be run within the transaction.
- with
Ecto.Multi
16.1 with a function
import Ecto.Changeset, only: [change: 2] Repo.transaction(fn -> Repo.update!(change(alice, balance: alice.balance - 10)) Repo.update!(change(bob, balance: bob.balance + 10)) end)
When a transaction succeeds, Repo.transaction returns a tuple {:ok, return_value_of_the_function}.
When a transaction fails:
- if an error is raised from the given function:
- the transaction will be rolled back automatically.
- the error will bubble up.
- if no error is raised from the given function:
- the transaction will NOT be rolled back automatically. Rollback should be specified explicitly with
Repo.rollback/1. Repo.transactionreturns a tuple{:error, value_specified_by_Repo_rollback}.
- the transaction will NOT be rolled back automatically. Rollback should be specified explicitly with
16.2 with Ecto.Multi
Ecto.Multi groups database operations into a data structure. Compare to the plain function described above, it has some advantages:
- you don't have to call Repo functions in the correct way carefully.
- write less code.
- easy to read.
- …
alias Ecto.Multi multi = Multi.new |> Multi.update(:from, change(alice, balance: alice.balance - 10)) |> Multi.update(:to, change(bob, balance: bob.balance + 10)) Repo.transaction(multi)
Always create %Ecto.Multi{} with Ecto.Multi.new/0 rather than %Ecto.Multi{}.
When a transaction succeeds, Repo.transaction returns a tuple with :ok and a map. The keys in the map are the unique names we provided to each operation in the Multi. The values are the return values for each of those operations. This makes it easy for us to grab the return values of any or all of the operations we ran.
When a transaction fails and you are using changesets, Repo.transaction returns a tuple with 4 items:
:error- the failed operation name, like above
:fromor:to - the value that caused failure
- a map containing changes to database (the changes have been rolled back, but Ecto provides them for you to inspect)
Ecto is designed to not waste database time. If the Ecto.Multi contains operations that use changesets, Ecto will make sure all the changesets are valid. If any are not, Ecto will not run a transaction at all.
When a transaction fails with an raised error:
- the transaction will be rolled back automatically.
- the error will bubble up.
16.3 which one should I use?
If you are only running a small number of operations and don't need to take different action depending on which operation succeeds or fails, using transaction with a function is enough.
For all other cases, you should consider
Ecto.Multi. It has a lot more flexibility, and the code needed to respond to different types of errors will be much cleaner and easier to follow.– Programming Ecto
16.4 executing non-database operations
Because Ecto don't know how to rollback non-database operations, you should run all of database operations first, then run non-database operations.
16.4.1 with a function
Using Ecto.Multi for non-database operations is recommended.
16.4.2 with Ecto.Multi
Read h Ecto.Multi.run for more details.
16.5 introspecting Ecto.Multi
%Ecto.Multi{} is a data structure that can be introspected.
Ecto team discourages inspecting or manipulating %Ecto.Multi{} directly, because the exact structure is subject to change.
Ecto team provides a function to introspect operations stored in %Ecto.Multi{}, read more details at Ecto.Multi.to_list/1.
17 Appendix
17.1 Naming conventions
- Migration
- tables' name -
pluralized_name
- tables' name -
- Schema
- module name -
SnakeSingularizedName - file name -
underscore_singularized_name - functions' arguments -
attrs
- module name -
- Context
- module -
SnakePluralizedName - file name -
underscore_pluralized_name - functions' arguments -
attrs
- module -
17.2 Related Mix tasks
Repo related:
ecto.gen.repo: Generates a new repository.
Database related:
ecto.create: Creates the repository storage.ecto.drop: Drops the repository storage.
Dump related:
ecto.dump: Dumps the repository database structure.ecto.load: Loads previously dumped database structure.
Migration related:
ecto.gen.migration: Generates a new migration for the repo.ecto.migrations: Displays the repository migration status.ecto.migrate: Runs the repository migrations.ecto.rollback: Rolls back the repository migrations.
Common aliases:
ecto.setup- An alias defined inmix.exs, generally:mix ecto.createmix ecto.migratemix run priv/repo/seeds.exs
ecto.reset- An alias defined inmix.exs, generally:mix ecto.dropmix ecto.setup
17.3 Schema related tips
17.3.1 #1
In Ecto, a table is not coupled to only one schema, developers are allowed to create more than one schema for a table.
17.3.2 #2
In Ecto, a schema is not coupled to only one update policy, developers is allowed to create more than one update policies for a schema. Each update policy has its own function which is filled with functions provided by Ecto.Changeset.
17.4 Adding Indexes
Although adding indexes makes insertions become slower, but it makes queries faster. So, in general applications(more queries than writes), it is still a good idea for adding it.
Generally, indexes are added to following columns:
- primary keys
- foreign keys
- columns need to be lookup
- columns need to be sorted
- columns which are used with
GROUP BY - …
By default, indexes of primary keys are created by Ecto automatically. But, indexes for foreign keys and other columns must be created by using Ecto.Migration.index manually.
Common indexes:
- unique indexes
- sorted indexes
- partial indexes
- covering indexes
Read more at:
17.5 About timestamps
By default, Ecto use :naive_datetime. But, I recommend using :utc_datetime or :utc_datetime_usec.
| Migration Type | PostgreSQL Data Type | Elixir Type |
|---|---|---|
:utc_datetime_usec |
timestamp without time zone |
DateTime |
:utc_datetime |
timestamp without time zone(0) |
DateTime |
:naive_datetime_usec |
timestamp without time zone |
NaiveDateTime |
:naive_datetime |
timestamp without time zone(0) |
NaiveDateTime |
Q: What is the meaning of (0)?
A: (0) means second precision. The microsecond part of timestamp is dropped.
17.5.1 Use :utc_datetime_usec globally
Apply on Migrations via configuration of Repo:
config :paper, Paper.Repo, migration_timestamps: [type: :utc_datetime_usec]
Apply on schemas according to official docs:
# Define a module to be used as base defmodule Paper.Schema do defmacro __using__(_) do quote do use Ecto.Schema @timestamps_opts [type: :utc_datetime_usec] end end end # Use MyApp.Schema to define new schemas defmodule Paper.CMS.Comment do use Paper.Schema schema "comments" do timestamps() end end
17.5.2 Use :utc_datetime_usec locally
Apply on Migrations:
defmodule Paper.Repo.Migrations.CreateComments do use Ecto.Migration def change do create table("comments") do # ... timestamps(type: :utc_datetime_usec) end end end
Apply on Schemas:
defmodule Paper.CMS.Comment do use Ecto.Schema schema "comments" do # ... timestamps(type: :utc_datetime_usec) end end
17.6 About using UUID as id globally
When using auto-incrementing number as primary keys, it introduces some problems:
- SCALING PROBLEM: At any given moment only one database server can generate the primary key. That means all writes have to go through a single server. That's bad news if you want to do thousands of writes per second.
- SECURITY PROBLEM: Bots and bad actors can guess private URLs.
How using UUIDs as primary keys solve the problems?
- SOLVE SCALING PROBLEM: All writes no longer have to go through a single database. You can spread them out across many servers. In addition they give you the flexibility to do things like generate the id of a record before its saved to the database. This might be useful if you want to send the record to a cache or search server, but don't want to wait for the database transaction to complete.
- SECURITY PROBLEM: UUID is random in personal view. It is hard to guess.
– Summarized from Simple tips to make scaling your database easier as you grow
Setup migrations:
config :paper, Paper.Repo, migration_primary_key: [name: :id, type: :binary_id]
Setup schemas:
# Define a module to be used as base defmodule Paper.Schema do defmacro __using__(_) do quote do use Ecto.Schema @primary_key {:id, :binary_id, autogenerate: true} @foreign_key_type :binary_id end end end # Now use Paper.CMS.Schema to define new schemas defmodule Paper.CMS.Comment do use Paper.Schema schema "comments" do belongs_to :post, Paper.CMS.Post end end
Then, just write any other things like before.
References:
By default, the UUID is generated by Elixir, if you want to generate UUID by database, read Ecto and Binary IDs Generated By PostgreSQL.
17.7 About using enum in Ecto
References:
17.7.1 method 1 - use builtin feature
Ecto 3.5 was released in October 2020, and it included the new Ecto.Enum module.
A migration:
defmodule MyApp.Repo.Migrations.AddRoleToUsers do use Ecto.Migration def up do execute("CREATE TYPE user_role AS ENUM ('admin', 'moderator', 'seller', 'buyer')") alter table(:users) do add :role, :user_role end end def down do alter table(:users) do remove :role, :user_role end execute("DROP TYPE user_role") end end
A schema:
defmodule MyApp.Accounts.User do use Ecto.Schema schema "users" do field :role, Ecto.Enum, values: [:admin, :moderator, :seller, :buyer] end end
17.7.2 method 2 - use EctoEnum
# lib/my_app/accounts/user_role.ex defmodule MyApp.Accounts.UserRole do use EctoEnum, type: :user_role, enums: [:admin, :moderator, :seller, :buyer] end # lib/my_app/accounts/user.ex defmodule MyApp.Accounts.User do use Ecto.Schema alias MyApp.Accounts.UserRole schema "users" do field :role, UserRole end end # priv/repo/migrations/20210102193646_add_role_to_users.exs defmodule MyApp.Repo.Migrations.AddRoleToUsers do use Ecto.Migration alias MyApp.Accounts.UserRole def change do UserRole.create_type() alter table(:users) do add :role, :user_role end end end
17.8 Setting default value for fields?
17.8.1 set default value in database level
Set default value for columns by using :default option of add macro in Ecto.Migration.
Furthermore, the default value set in this way is used when inserting new rows, including:
- insert new rows.
- insert new columns for existing rows.
17.8.2 set default value in application level
There're two ways to set default value in application level:
- use
:defaultoption offieldmacro inEcto.Schema. - use
Ecto.Changeset.put_changeor similar functions.
Default values set by :default option will be evaluated at compilation time, so you shouldn't use them if you need dynamic values.
If you need dynamic values, Ecto.Changeset.put_change or similar functions is preferred.
17.8.3 which one should I use?
If you have multiple applications using the same database, and:
- if they need same default values, default values can be set in schemas or migrations.
- if they need different default values, default values should be set in schemas.
If you only have one application, default values can be set in schemas or migrations.
When possible, I prefer using schemas. Because in this way, I can reduce the frequency of changing database, which makes me iterate application faster.
17.9 Commonly used constraints
We have known the usage of unique_constraint/3. In this section, we will introduce other commonly used constraints.
17.9.1 foreign_key_constraint/3
This function checks foreign key constraint in the given field.
When inserting / updating a post, check if the foreign key is valid:
post |> change() |> foreign_key_constraint(:author_id) |> Repo.insert!()
When deleting a author, check if there's no associated post:
author |> change() |> foreign_key_constraint( :posts, name: :posts_author_id_fkey, message: "still exists" ) |> Repo.delete!()
As you can see, using foreign_key_contraint/3 when deleting a record, we have to define the contraint name manually. That is verbose. So I prefer using no_assoc_constraint/3.
17.9.2 assoc_constraint/3
This function checks if the associated field exists. It is generally used when inserting or updating record.
assoc_constraint/3 is similar to foreign_key_constraint/3, but field of foreign key is inferred from association definition rather than being specified exactly.
When inserting / updating a post, check if the foreign key is valid:
post |> change() |> assoc_constraint(:author) // infer the foreign key from association name |> Repo.insert!()
17.9.3 no_assoc_constraint/3
Check the associated field doesn't exist. It is generally used when deleting record.
Define the foreign key:
create table("posts") do add :author_id, references("authors") end
When deleting a record, ensure that no child exists:
author |> change() |> no_assoc_constraint(:posts) |> Repo.delete!()
17.10 Don't use constraints all the time
Using changeset constraints only makes sense if the error message can be something the user can take action on.
– Programming Ecto
Constraints are useful when converting errors into human-readable messages. But you don't have to use them all the time.
Give it an example.
In our blogging system, every comment belongs to a post. If not, it can only be a bug in our application or a data-integrity issue. In such case, the user can do nothing to fix the error, so crashing is the best option. You shouldn't convert such kind of errors into human-readable messages any more. Although you convert them, and notify users, users can do nothing to fix these errors.
17.11 Common use cases of Ecto
- Data validation
- Database interaction
In order to split the concerns, official team created two packages:
ectoecto_sql
18 License
Except the quotes, the rest parts of this book are restricted by CC BY-NC-SA 4.0.